
0x01前情提要
目前在做一个非结构化数据解析项目,非结构化数据中占比最大的主要是PDF格式。
在解析过程中会使用pymupdf对PDF中的文本和图像做初步解析

api会返回一个类似上图结构的字典,
层级大概是doc→page→block→line→span→char
我们的解析逻辑代码会根据pymupdf给出的初步解析dict进行分析,生成一个中间态的dict,
但是这个中间态的dict因为包含了太多的过程数据,导致大小膨胀的十分可怕,在通常情况下这个dict是pdf源文件的10倍左右,在极端情况下可以达到30倍大小。


目前批量任务是通过spark运行的,1000w任务在切片30w task时,每task约30余条pdf,在起先多次测试爆掉内存后(从初始的10core40G到5core100G),自爆自弃的配置了1core40G的豪华配置,只想先把任务跑起来,但是还是出现了jvm虚拟机被爆了的情况
24/01/14 04:31:12 ERROR SparkUncaughtExceptionHandler: [Container in shutdown] Uncaught exception in thread Thread[stdout writer for /share/dataproc/envs/py3.10/bin/python,5,main]
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at java.lang.StringCoding.encode(StringCoding.java:350)
at java.lang.String.getBytes(String.java:941)
at org.apache.spark.unsafe.types.UTF8String.fromString(UTF8String.java:139)
at org.apache.spark.sql.execution.python.EvaluatePython$$anonfun$$nestedInanonfun$makeFromJava$11$1.applyOrElse(EvaluatePython.scala:149)
at org.apache.spark.sql.execution.python.EvaluatePython$.nullSafeConvert(EvaluatePython.scala:213)
at org.apache.spark.sql.execution.python.EvaluatePython$.$anonfun$makeFromJava$11(EvaluatePython.scala:148)
at org.apache.spark.sql.execution.python.EvaluatePython$$$Lambda$851/617702869.apply(Unknown Source)
at org.apache.spark.sql.execution.python.EvaluatePython$$anonfun$$nestedInanonfun$makeFromJava$16$1.applyOrElse(EvaluatePython.scala:195)
at org.apache.spark.sql.execution.python.EvaluatePython$.nullSafeConvert(EvaluatePython.scala:213)
at org.apache.spark.sql.execution.python.EvaluatePython$.$anonfun$makeFromJava$16(EvaluatePython.scala:182)
at org.apache.spark.sql.execution.python.EvaluatePython$$$Lambda$929/208188683.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.$anonfun$applySchemaToPythonRDD$2(SparkSession.scala:802)
at org.apache.spark.sql.SparkSession$$Lambda$930/21820570.apply(Unknown Source)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.ContextAwareIterator.hasNext(ContextAwareIterator.scala:39)
at org.apache.spark.api.python.SerDeUtil$AutoBatchedPickler.next(SerDeUtil.scala:89)
at org.apache.spark.api.python.SerDeUtil$AutoBatchedPickler.next(SerDeUtil.scala:80)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.api.python.SerDeUtil$AutoBatchedPickler.foreach(SerDeUtil.scala:80)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:320)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:734)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:440)
at org.apache.spark.api.python.BasePythonRunner$WriterThread$$Lambda$841/158147681.apply(Unknown Source)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:2088)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:274)
通过监控发现,单个task在极限状态下占用内存达到了28G,虽然没有超出40G的分配上限,但还是被爆掉了,问了gpt才明白,java存储string是通过byte数组实现的,这个数组最大长度是int类型的最大值即Integer.MAX_VALUE ,也就是2^31 - 1,这个大小约等效2G大小的文本文件。
复测了导致java.lang.OutOfMemoryError的PDF文件,在本地通过python程序可以正常解析,解析后的中间态dict一个是900M+,一个是1.5G左右,考虑到单个task存在30余条pdf,因此爆掉java的string也不是那么让人意外了。
0x02 解决方案选型
这种情况下,很难在一个executor配置更多的core增加任务的并行程度,
和其他的开发同学讨论过,中间态dict太大了,可不可以不落地,但是哒咩~
这种问题怎么能难道聪明的myhloli酱呢,总有办法解决超大字典的落地问题的,
网上搜了一下json压缩,有人提到两个方案cjson和json.hpack(jsonh),但是经过测试这俩方案都有局限性,不太适合逻辑结构异常复制的json进行压缩
随手在explorer中右键点了下压缩,没想到效果意外的还不错

但是桌面压缩的速度有点慢到离谱了 360压缩的问题,windows自带的压缩还是挺快的
试着直接在代码中使用gzip压缩
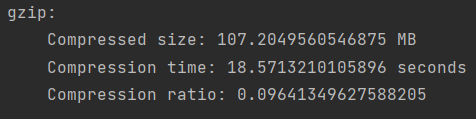
gzip默认是用level9的,914m压缩到了107m,耗时18s,看上去感觉还可以,
讨论后,初步决定使用无损压缩方案直接对json字符串进行压缩后存储base64文本的方案。
0x03 压缩方案选型
既然选用了压缩方案,科学的实施过程是先选择一款优秀的压缩算法再进行下一步
一款优秀的压缩算法应有的特性包含两点:
1、压缩比高,也就是压缩完成之后的文件要尽可能小
2、速度快,在相同压缩比的前提下,压缩速度要尽可能快
gzip的优势是python库内置,无需引入第三方依赖,python同时也内置了lzma库,
这两个库各有特点,gzip速度稍快,压缩率稍低,lzma速度较慢,但是压缩率更高
除了内置的这两款压缩库以外,另外也通过调研,补充两个现代的、广泛使用的压缩库参与对比。
Brotli:
https://github.com/google/brotli
Brotli是Google开发的一种无损压缩算法,最初设计用于HTTP内容编码。Brotli在压缩效率和速度之间提供了一种良好的平衡,特别是在处理文本和HTML内容时。它提供了不同级别的压缩选项,允许用户在压缩速度和压缩效果之间做出选择。此外,由于Brotli的广泛支持,它可以用于各种应用中,包括Web服务器和浏览器。
Zstandard:
https://github.com/facebook/zstd
Zstandard是由Facebook开发的一种无损压缩算法,设计用于实现高压缩比和高速度。Zstd提供了一种广泛的压缩级别选择,允许用户在压缩速度和压缩效果之间做出权衡。与Brotli相比,Zstd通常能够提供更快的压缩和解压缩速度,尤其是在处理大型数据集时。
0x04 代码编写
现在AI发展的这么快,简单的测试代码已经难不倒AI了,作为一个AI领域工程师,代码还要自己写那可太out了,全部交给AI来搞定
import gzip
import time
import brotli
import zstandard
import lzma
import json
import os
import base64
# 定义压缩函数
def compress_with_method(input_str, output_file, compression_method, **kwargs):
start = time.time()
compressed = compression_method(input_str.encode(), **kwargs)
with open(output_file, 'wb') as f_out:
f_out.write(base64.b64encode(compressed))
end = time.time()
compressed_size = os.path.getsize(output_file)
original_size = len(input_str.encode())
compression_ratio = compressed_size / original_size
return end - start, compression_ratio
def compress_with_gzip(input_str, output_file, compresslevel):
return compress_with_method(input_str, output_file, gzip.compress, compresslevel=compresslevel)
def compress_with_brotli(input_str, output_file, quality):
return compress_with_method(input_str, output_file, brotli.compress, quality=quality)
def compress_with_zstandard(input_str, output_file, level):
cctx = zstandard.ZstdCompressor(level=level)
return compress_with_method(input_str, output_file, cctx.compress)
def compress_with_lzma(input_str, output_file, preset):
return compress_with_method(input_str, output_file, lzma.compress, preset=preset)
# 定义测试函数
def test_compression(compression_name, compression_func, param_range, file, json_str, results):
for param in param_range:
output_file = f'test_{compression_name}_{param}_{file}.compressed'
elapsed_time, compression_ratio = compression_func(json_str, output_file, param)
print(f"{compression_name} level {param} for {file}:")
print(f"\tCompressed size: {os.path.getsize(output_file) / 1024 / 1024} MB")
print(f"\tCompression time: {elapsed_time} seconds")
print(f"\tCompression ratio: {compression_ratio}")
results.append([file, f'{compression_name}_{param}', elapsed_time, os.path.getsize(output_file), compression_ratio])
# 定义文件列表
files = ["simple1.json", "simple2.json"]
results = []
# 对每个文件进行压缩
for file in files:
# 将测试数据转换为 JSON 字符串
with open(file, 'r', encoding='utf-8') as f_in:
json_str = json.dumps(f_in.read())
# 计算原始数据大小
original_size = len(json_str.encode('utf-8'))
# 测试 brotli 的 quality(0~11)
test_compression('brotli', compress_with_brotli, range(0, 12), file, json_str, results)
# 测试 zstandard 的 level(-5~22)
test_compression('zstandard', compress_with_zstandard, range(-5, 23), file, json_str, results)
# 测试 gzip 的 level(0-9)
test_compression('gzip', compress_with_gzip, range(0, 10), file, json_str, results)
# 测试 lzma 的 level(0-9)
test_compression('lzma', compress_with_lzma, range(0, 10), file, json_str, results)
# 导入 csv 模块
import csv
# 用 'w' 模式打开一个名为 'compression_results.csv' 的文件
with open('compression_results.csv', 'w', encoding='utf-8', newline='') as f_out:
# 创建一个 csv 写入对象
writer = csv.writer(f_out)
# 写入表头
writer.writerow(['file', 'algorithm', 'time', 'size', 'ratio'])
# 写入所有的结果
writer.writerows(results)
全部代码写完不超过10分钟,直接开run
0x05 统计分析
测试共使用两个样例,simple1.json(914MB)和simple2.json(1.49GB)
测试机器windows 11/i7-11700 4.6GHZ/python 3.11/Brotli 1.1.0/python-zstandard 0.22.0
数据跑完,发现一个诡异的东西,gzip在level 0下跑出来的东西比原本的内容还大

统计的时候排掉gzip0先画张图看看
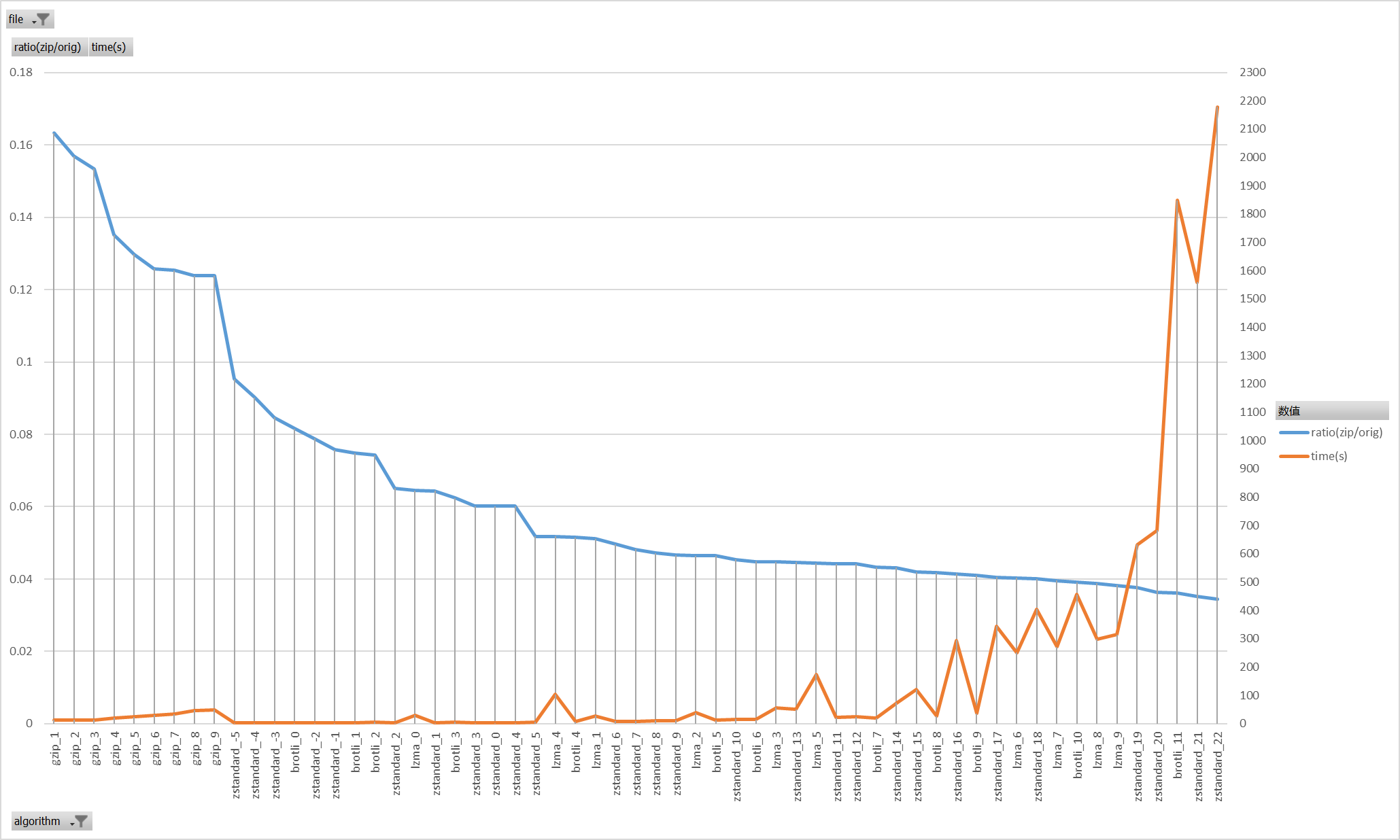
从图里可以比较直观的看出来,随着压缩等级的增加,压缩率越来越逼近极限水平,压缩耗时也成倍的增加
同时可以发现,gzip即便是用最高的压缩级别,压缩率也不如其他三种算法的任何一档,因此可以直接把gzip方案排除掉
同时把耗时超长至不可接受的几个算法等级排除掉再画张图

这样再看会比较直观,可以看出来对于目标json文件的压缩,极限的压缩率在0.04附近
在接近极限压缩率的时候,brotli_9表现出了较高的性价比
在这张图上,time的纵坐标依然是较高的水平,我们再一步过滤掉高耗时的一些方案
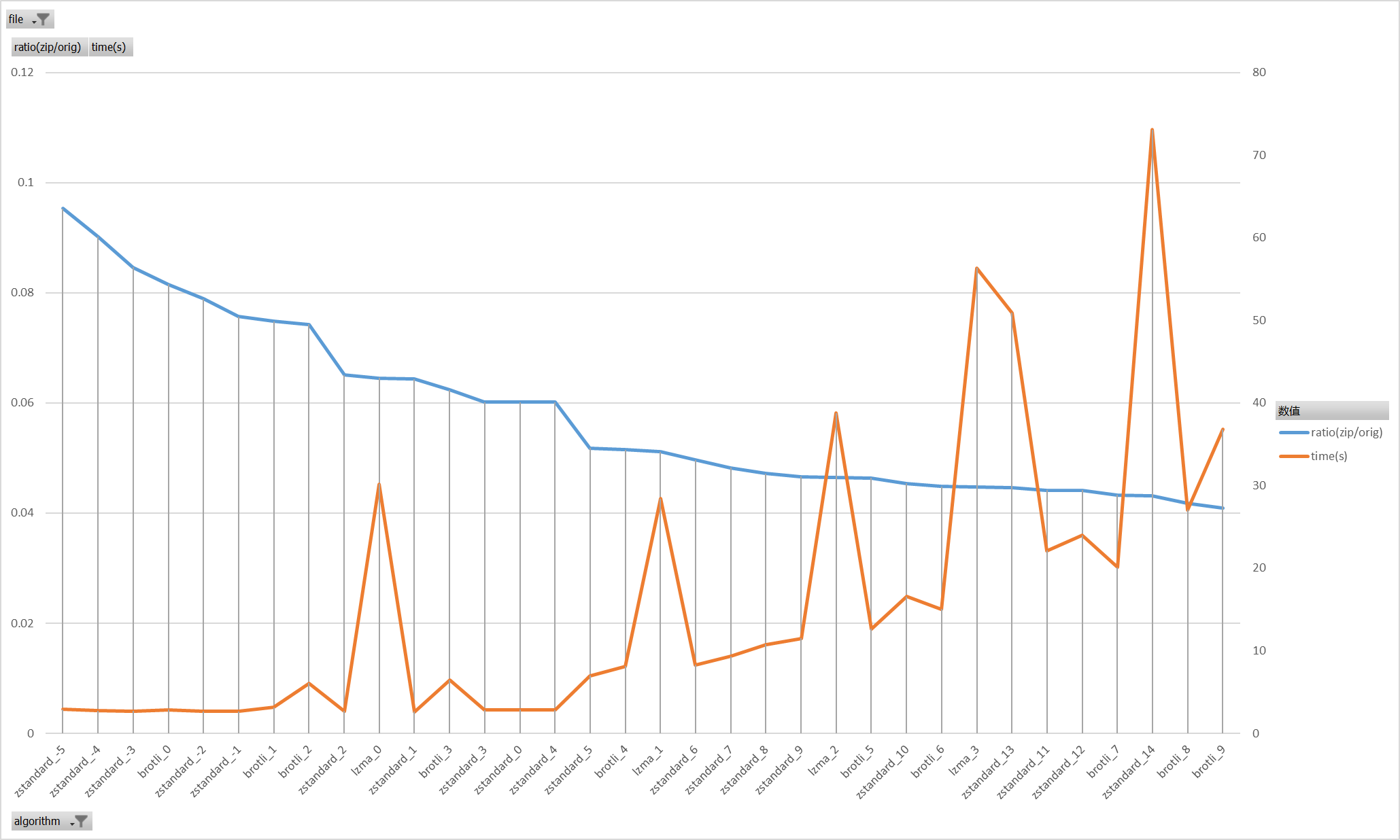
过滤掉耗时100秒以上的方案,结果少了很多,好像进了决赛圈一样
几个怪异的尖尖好像都是lzma带来的,先排掉lzma,再排掉两个高level的zstandard_13和zstandard_14
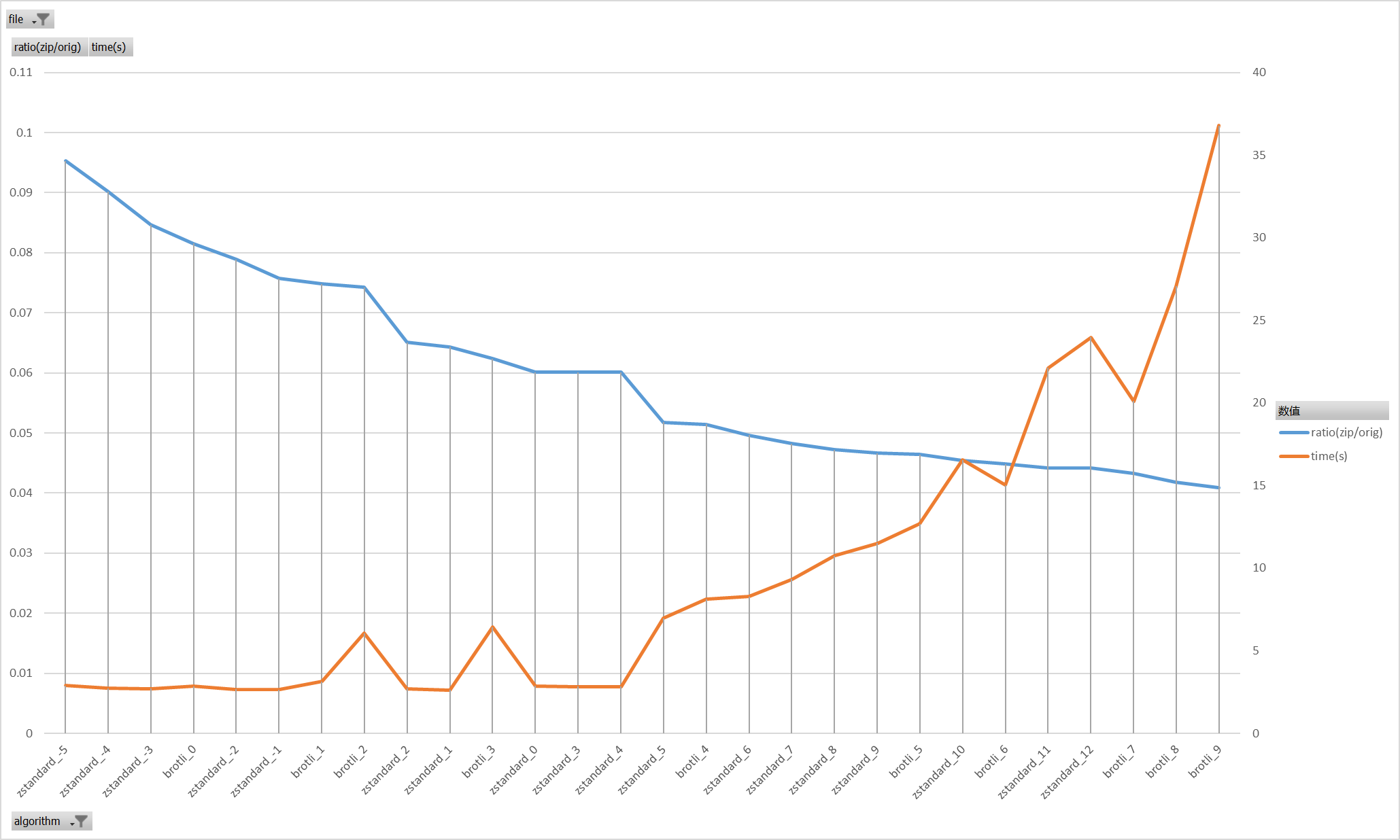
剩下这张图的结果更就比较明显了
zstandard_0/zstandard_3/zstandard_4在极低耗时下实现了0.06的压缩率
zstandard_5/zstandard_6/brotli_4 在较低耗时下实现了0.05附近的压缩率
追求更高压缩比的情况下brotli_6/brotli_7提供了较好的性价比
因为选择的测试样本是比较极端的1G+的json,实际使用中存在另外两个要点,
一是其他json没有这么大,可能普遍在几分之一的大小,二是单本PDF的解析时间也远超压缩所用的耗时,压缩耗时是个比较敏感的参数,但是也没有那么敏感。
综合考量,最后选择了brotli_7brotli_6方案作为json数据的压缩方案。

